Chapter 6. Mechanisms of Gene Expression
The flow of genetic information
Otherwise known as the Central Dogma of Molecular Biology (Crick, 1970), the flow of genetic information in living cells proceeds from DNA to RNA to protein. Since the final folding of polypeptides is the result of interaction of the R groups of amino acids that polypeptides are made of, the last element in the three-step genetic information flow is more correctly referred to as being a polypeptide that makes up a protein. Genetics contains no information about the protein function, only the protein structure.
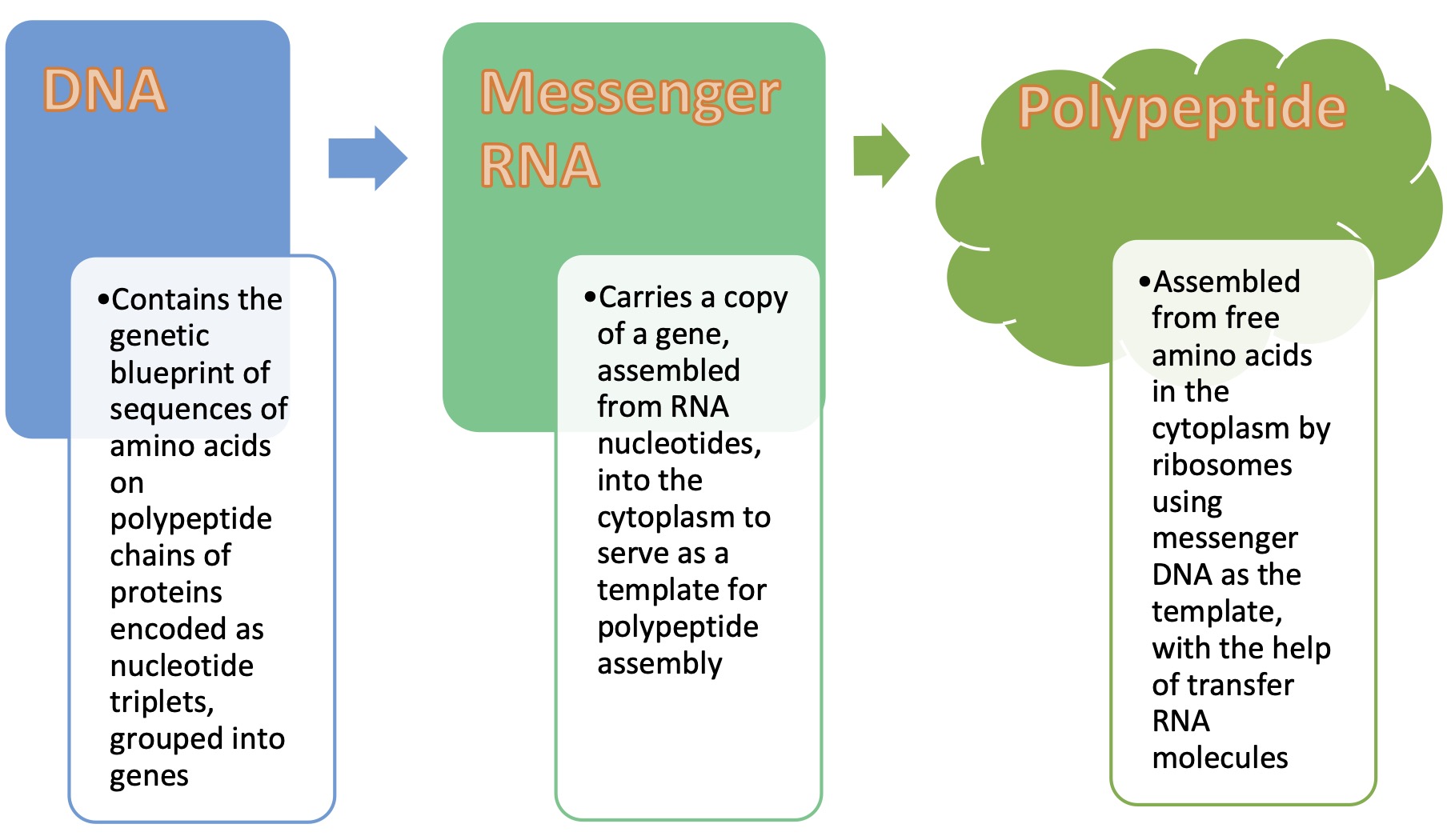
The transfer of genetic information consists of three stages. It begins with the DNA replication, which was discussed earlier. The other two stages convert DNA information into a sequence of RNA nucleotides (transcription), which is subsequently converted into a sequence of amino acids to produce a polypeptide molecule (translation). Transcription and translation are the required steps to express genetic information as a functional product or a process that leads to the outward appearance (i.e., the phenotype) of most organismal traits. This gene expression begins with transcription of DNA into an RNA molecule, which is a tightly regulated process.
Transcriptional regulatory elements
In eukaryotes, RNA polymerase, and therefore the initiation of transcription, needs to be able to find a gene to be transcribed among the billions of nucleotides in the genome. To do that, it relies on specific activity of various regulatory elements. With respect to their location relative to the gene, regulatory elements can be proximal and distal. They can also be cis- and trans-acting. (Cis: located on the same DNA molecule; trans: located on different molecules.) The main groups of regulatory sequences are promoters and enhancers.
Promoters are regions of DNA that promote transcription and, in eukaryotes, are found at -30, -75, and -90 base pairs upstream from the transcription initiation site (Transcription Start Site, TSS). Promoter elements can be found immediately next to TSS or at a distance from it. Proximal promoter elements are regions located up to a few hundred base pairs from the core promoter, and typically contain multiple binding sites for other regulatory elements. Distal promoters are located further away.
The core promoter is the region at the start of a gene that serves as the docking site for the transcriptional machinery. The core promoter region is located most proximal to the start codon (ATG, see Chapter 5) and contains the RNA polymerase binding site, TATA box, and TSS. When RNA polymerase binds to the core promoter region stably, the transcription of the gene can initiate. The TATA box is a DNA sequence (5′-TATAAA-3′) within the core promoter region where general transcription factor proteins and histones can bind. Histones are proteins found in eukaryotic cells that package DNA into nucleosomes. Histone binding prevents the initiation of transcription whereas transcription factors promote the initiation of transcription. The most 3′ portion (closest to the gene’s start codon) of the core promoter is the TSS which is where transcription actually begins.
Core promoters are essential for transcription initiation. RNA polymerase is able to bind to core promoters in the presence of various specific transcription factors.
The most common component of core promoter in eukaryotes is a short DNA sequence known as a TATA box, found 25-30 base pairs upstream from TSS. The TATA box is the binding site for a transcription factor known as the TATA-binding protein (TBP), which is itself a subunit of another transcription factor, called Transcription Factor II D (TFIID).
Enhancers are genetic sequences that can be recognized by activators, which are proteins with DNA-binding capability (transcription factors) that increase the rate of transcription from a specific gene upon binding to an activator sequence.
Other transcriptional regulatory elements include silencers and insulators. Silencers are distal genetic sequences that can repress gene transcription upon binding with proteins called repressors. Insulators are nucleotide sequences that function to block genes from being affected by the transcriptional activity of neighboring genes.
Transcription factors
In molecular genetics, a transcription factor (sometimes called a sequence-specific DNA-binding factor) is a protein that binds to specific DNA sequences, thereby controlling the flow (or transcription) of genetic information from DNA to mRNA. Transcription factors perform this function alone or with other proteins in a complex, by promoting (as an activator), or blocking (as a repressor) the recruitment of RNA polymerase (the enzyme that performs the transcription of genetic information from DNA to RNA) to specific genes. When binding to insulator sequences, transcription factors prevent co-transcription of neighboring genes along with the target gene.
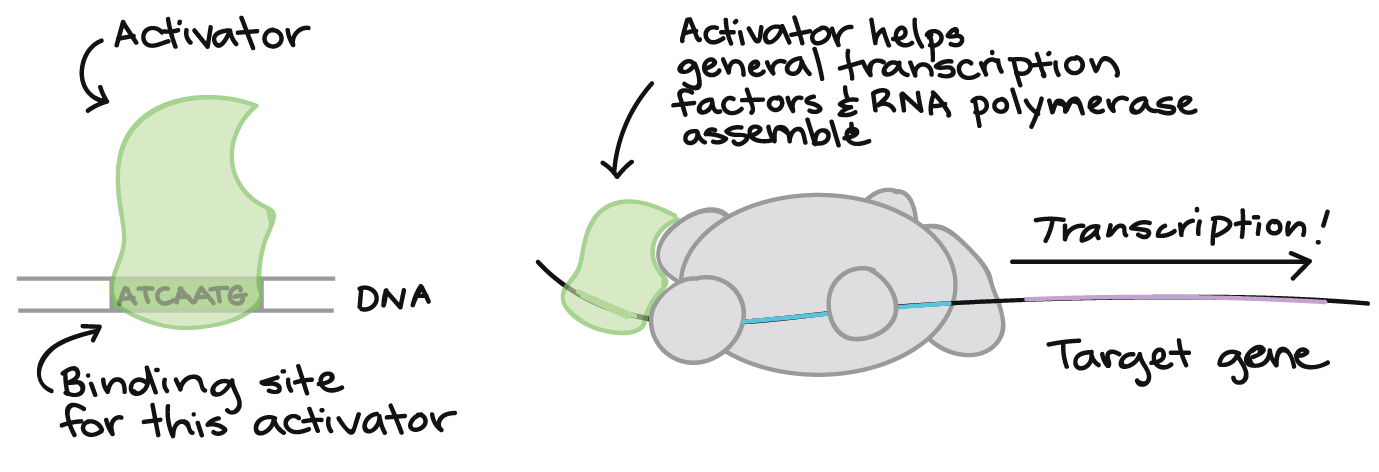
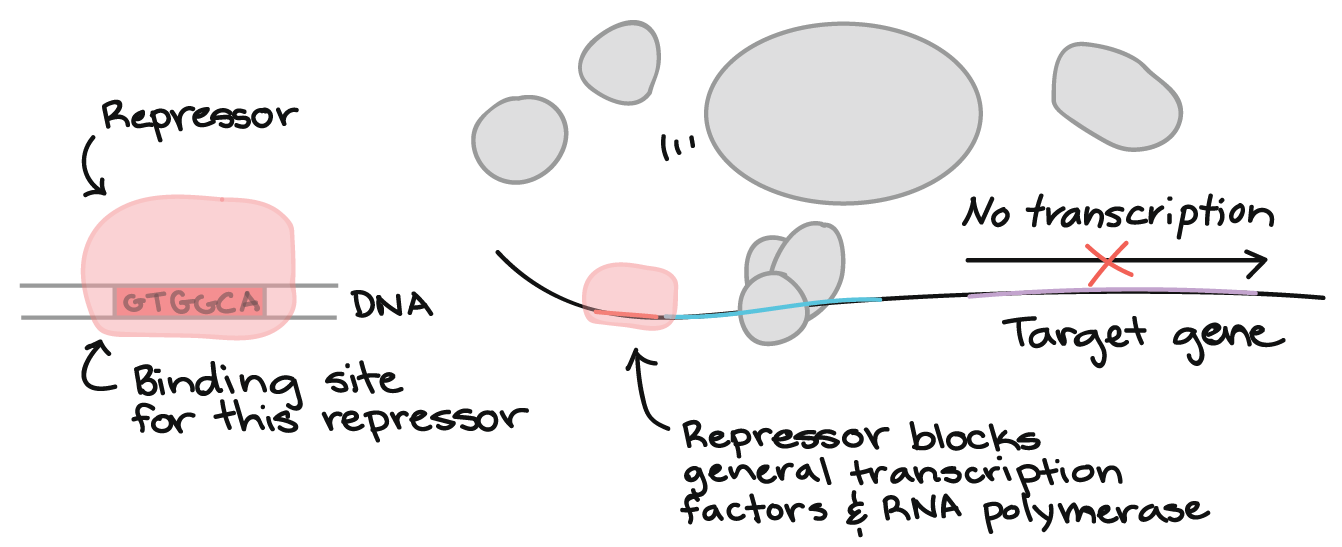
Sometimes, all three functions can be accomplished by the same transcription factor. For example, a gene called CTCF encodes a transcriptional regulator that is able to to bind different DNA target sequences and proteins. Depending upon the context of the site, the protein can bind a histone acetyltransferase (HAT)-containing complex and function as a transcriptional activator or bind a histone deacetylase (HDAC)-containing complex and function as a transcriptional repressor. If the protein is bound to a transcriptional insulator element, it can block communication between enhancers and upstream promoters, thereby selectively regulating downstream gene expression.
Transcription factors directly control when, where, and the extent to which genes are expressed. Signal transduction pathways are responsible for either activating or inhibiting many of them. Transcription factors are also regulated by cofactors, forming complexes that can activate or inhibit transcriptional activity. Many transcription factors, such as nuclear receptors, re- side in the cytoplasm and enter the nucleus upon activation (e.g., ligand binding). Posttranslational modifications and coregulating proteins provide additional layers of regulation. Transcription factors are involved in a wide variety of processes, such as development, stress responses, and immunity. Activation or inhibition of transcription factors is often dysregulated during oncogenesis. Transcription factors can also be dysregulated during developmental processes, promoting or inhibiting cellular differentiation. Analyzing the expression, regulation, activity, and sequence of transcription factor genes can help determine their relative importance to the biology of the cellular or disease processes under study.
A defining feature of transcription factors is that they contain one or more DNA-binding domains (DBDs), which attach to specific sequences of DNA adjacent to the genes that they regulate. Additional proteins such as coactivators, chromatin remod- elers, histone acetylases, deacetylases, kinases, and methylases, while also playing crucial roles in gene regulation, lack DNA-binding domains, and, therefore, are not classified as transcription factors.
Transcription factors are essential for the regulation of gene expression and are, as a consequence, found in all living organisms. The number of transcription factors found within an organism increases with genome size, and larger genomes tend to have more transcription factors per gene.
There are approximately 2,600 proteins in the human genome that contain DNA-binding domains, and most of these are presumed to function as transcription factors. Therefore, approximately 10% of genes in the genome code for transcription factors, which makes this family the single largest family of human proteins. Furthermore, genes are often flanked by several binding sites for distinct transcription factors, and efficient expression of each of these genes requires the cooperative action of several different transcription factors. Hence, the combinatorial use of a subset of the approximately 2,000 human transcription factors easily accounts for the unique regulation of each gene in the human genome during development.
Transcription factors use a variety of mechanisms for the regulation of gene expression. These mechanisms include:
- Stabilize or block the binding of RNA polymerase to DNA.
- Recruit coactivator or corepressor proteins to the transcription factor DNA complex.
- Catalyze the acetylation or deacetylation of histone proteins. The transcription factor can either do this directly or recruit other proteins with this catalytic activity.
Many transcription factors use one or the other of two opposing mechanisms to regulate transcription:
- Histone acetyltransferase (HAT) activity – acetylates histone proteins, which weakens the association of DNA with histones, which make the DNA more accessible to transcription, thereby up-regulating transcription;
- Histone deacetylase (HDAC) activity – deacetylates histone proteins, which strengthens the association of DNA with histones, which make the DNA less accessible to transcription, thereby down-regulating transcription.
Stages Of Genetic Expression
Transcription
Transcription is the process of creating a complementary RNA copy of a sequence of DNA. Transcription is the first step leading to gene expression. Genetic transcription converts the sequence of DNA nucleotides containing information about polypeptide structure into a corresponding sequence of RNA nucleotides. As opposed to DNA replication, transcription results in an RNA complement that includes uracil (U) in all instances where thymine (T) would have occurred in a DNA complement. Transcription takes place inside the nucleus.
During transcription, the genetic information coded in the DNA is transferred to an RNA molecule. The RNA molecule produced in the course of transcription (called a messenger RNA or mRNA) can leave the nucleus (the site of DNA transcription in eukaryotes) and attach to the ribosomes, where free amino acids are joined together according to the nucleotide sequence of a particular mRNA molecule.
RNA nucleotides are linked together by the transcription enzyme RNA polymerase.
RNA polymerase synthesizes mRNA using the non-coding (antisense) strand of DNA as the template. The other DNA strand is called the coding strand, because it is the strand that carries the genetic code for the protein being expressed and its sequence is the same as the newly created RNA transcript (except for the substitution of uracil for thymine). The use of only the 3′ → 5′ strand produces a continuous mRNA molecule, thus eliminating the need for the Okazaki fragments seen in DNA replication. As in DNA replication, DNA is read from 3′ → 5′ during transcription. Mean- while, the complementary RNA is created from the 5′ → 3′ direction.
Transcription is divided into three main stages: initiation, elongation and termination.
Initiation
After TFIID binds to the TATA box via the TBP, five more tran- scription factors and RNA polymerase combine around the TATA box in a series of stages to form a preinitiation complex.
One transcription factor, DNA helicase, has helicase activity and so is involved in the separating of opposing strands of double-stranded DNA to provide access to a single-stranded DNA template. However, only a low, or basal, rate of transcrip- tion is driven by the preinitiation complex alone. Other proteins known as activators and repressors, along with any associated coactivators or corepressors, are responsible for modulating transcription rate.
Transcription factors mediate the binding of RNA polymerase and the initiation of transcription. Only after certain transcription factors are attached to the promoter does the RNA polymerase bind to it. The completed assembly of transcription factors and RNA polymerase bind to the promoter, forming a transcription initiation complex.
Elongation
As transcription proceeds, RNA polymerase traverses the tem- plate strand and uses base pairing complementarity with the
DNA template to create an RNA copy. Although RNA po- lymerase traverses the template strand from 3′ → 5′, the coding (non-template) strand and newly-formed RNA can also be used as reference points, so transcription can be described as occur- ring 5′ → 3′. This produces an RNA molecule from 5′ → 3′, an exact copy of the coding strand (except that thymines are re- placed with uracils, and the nucleotides are composed of a ri- bose (5-carbon) sugar where DNA has deoxyribose (one less oxygen atom) in its sugar-phosphate backbone).
Messenger RNA transcription can involve multiple RNA polymerases on a single DNA template and multiple rounds of transcription (amplification of particular mRNA), so many mRNA molecules can be rapidly produced from a single copy of a gene.
Elongation also involves a proofreading mechanism that can replace incorrectly incorporated bases. In eukaryotes, this may correspond with short pauses during transcription that allow appropriate RNA editing factors to bind. These pauses may be intrinsic to the RNA polymerase or due to chromatin structure.
Termination
RNA transcription stops when the RNA polymerase encounters a G-C-rich inverted repeat followed by a run of uracil nucleotides. The G-C rich repeat forms a hairpin (or stem-loop structure) via internal complementary binding within the inverted repeat sequence. When the hairpin forms, the mechanical stress breaks the weak rU-dA bonds, now filling the DNA-RNA hybrid. This pulls the poly-U transcript out of the active site of the RNA polymerase, in effect, terminating transcription. In the “Rho- dependent” type of termination, a protein factor called “Rho” destabilizes the interaction between the template and the mRNA, thus releasing the newly synthesized mRNA from the elongation complex.
Transcription termination in eukaryotes is less understood but involves cleavage of the new transcript followed by template- independent addition of As at its new 3′ end, in a process called polyadenylation.
Post-transcriptional mRNA modification
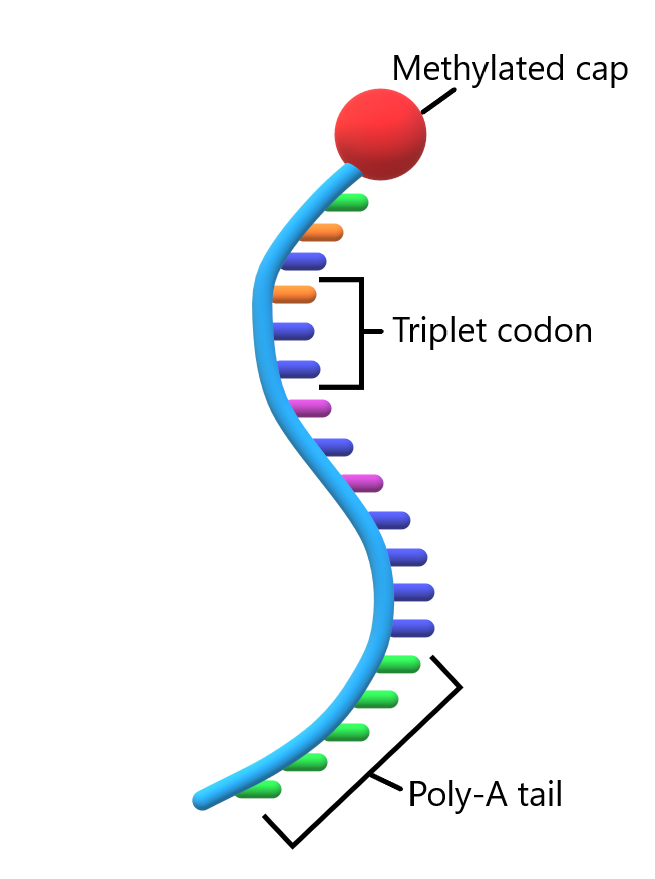
Before mRNA can leave the nucleus and enter the cytoplasm where protein synthesis takes place, mRNA needs to be adequately prepared for the journey. In its primary transcript state, mRNA (at this stage referred to as pre-mRNA) contains introns that need to be removed before protein synthesis begins. The mRNA molecule also needs to be chemically protected against the enzymes in the cytoplasm that destroy any nucleic acid sequence they encounter (as part of cellular defense mechanism). The modifications primary mRNA transcript undergoes before leaving the nucleus include spicing and addition of a 5′ methylated “cap” and a 3′ poly-A “tale”.
Pre-mRNA modification: splicing
The mRNA splicing is an important step in creating the mRNA that is involved in protein synthesis, via the process of translation. Key factors in this process include: RNA, possessing introns and exons, and the spliceosome.
Several signals exist within the intron that are used in the splic- ing process. From the 5′ end of the intron, these are, GU, the A branch site, a pyrimidine-rich region, and the 3′ AG. The AG and GU sequences define the beginning and end of the intron.
Splicing is mediated by the spliceosome, which consists of several protein-RNA complexes. The first step involves two complexes that bind near the GU sequence. The RNA in then looped, and three other protein-RNA complexes bind. This final complex then undergoes a conformation change. As the spliced mRNA is released from the spliceosome, the intron de- branches, and is then degraded.
Introns are non-coding RNA sequences that must be removed before translation. The process of removing the intron is called splicing. The intron is then cleaved at the 5′ GU sequence and forms a lariat at the A branch site. The 3′ end of the intron is next cleaved at the AG sequence, and the two exons are ligated together.
Selective removal of introns can add to the diversity of polypeptides that can be encoded on the same gene. If an intron is left in the mature mRNA molecule after splicing, it will be interpreted by the ribosome during translation as the end of translation sequence. Thus, an un-removed intron would function much like a stop codon during translation. Therefore, a selective removal of introns from the primary mRNA transcript can result in mature mRNA of different lengths, thus leading to the translation of polypeptides of different sizes.
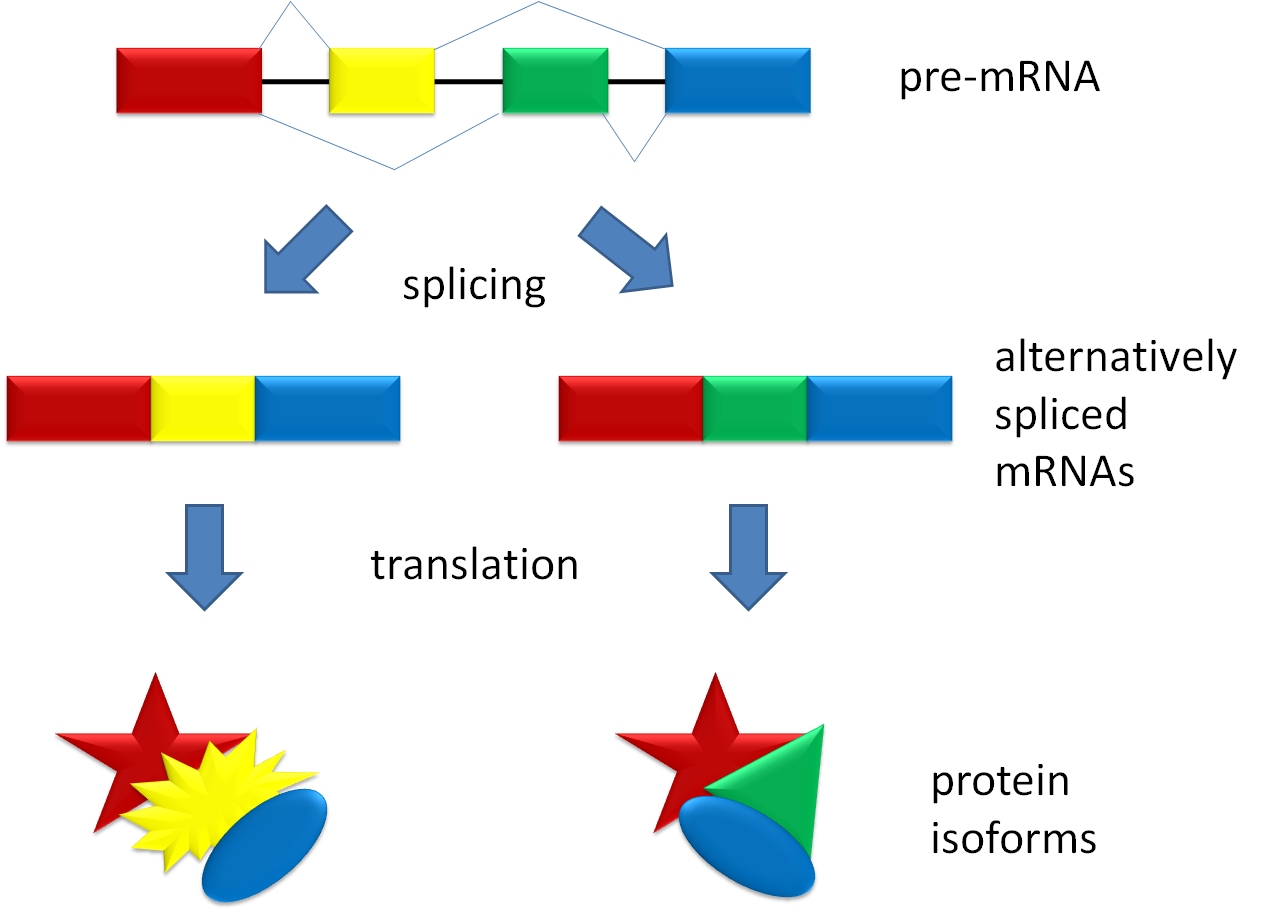
Post-transcriptional mRNA processing also includes the addition of a 5’ “cap” and a poly-adenine (poly-A) tail to the mRNA molecule.
Pre-mRNA modification: 5′ End Capping and 3′ Poly-A Tail
Post-transcriptional processing of the 5′ end of the RNA product of DNA transcription comes in the form of a process called the 5′ cap. At the end of transcription, the 5′ end of the RNA transcript contains a free triphosphate group since it was the first incorporated nucleotide in the chain. The capping process replaces the triphosphate group with another structure called the “cap”. The cap is added by the enzyme guanyl transferase. This enzyme catalyzes the reaction between the 5′ end of the RNA transcript and a guanine triphosphate (GTP) molecule.
Post-transcriptional RNA processing at the opposite end of the transcript comes in the form of a string of adenine bases attached to the end of the synthesized RNA chain. This string of adenine to the 3′ end of the mRNA molecule is called the “poly A tail”. The addition of the adenines is catalyzed by the enzyme poly (A) polymerase, which recognizes the sequence AAUAAA as a signal for the addition. The reaction proceeds through mechanism similar to that used for the addition of nucleotides during transcription.
Translation
Genetic translation is a conversion of nucleotide sequence of mRNA into a sequence of amino acids joined together via peptide bonds to form a polypeptide. Translation takes place in the cytoplasm and involves mRNA, a special type of RNA mole- cules called transport RNA (tRNA), ribosomes, as well as free amino acids found in the cytoplasm.
Translation takes place on the ribosomes in the cytoplasm. (RNA is also a part of the ribosomal structure! It’s called the ribo- somal RNA, or rRNA.)
A special RNA molecule called transfer RNA or tRNA, mediates the translation of the triplet code of amino acids into the amino acid sequence.
As the mRNA passes through the ribosomes during translation, the tRNA molecules recognize the codons on the mRNA and bring the corresponding amino acids to the assembly site. Each following amino acid in the polypeptide sequence is attached to the previous one by a peptide bond.
When the translation machinery reaches a stop codon on the mRNA, the translation stops and the newly formed polypeptide separates from the ribosomes and dispatches into the cytoplasm for further processing. Polypeptide chain coils and folds spontaneously, due to the nature of its chemical bonds, forming a functional protein of specific conformation.
Key Takeaways
- The Central Dogma of Molecular Biology states that genetic information flows only in one direction, from DNA, to RNA, to protein.
- Eukaryotic gene expression is regulated by promoter regions, enhancer, silencer and insulator DNA sequences and transcription factors that bind to these sequences.
- Transcription factors bind to enhancer, silencer, insulator, or promoter regions of DNA adjacent to the genes that they regulate. Depending on the transcription factor and the DNA region the transcription factor binds to, the transcription of the adjacent gene is either up- or down-regulated. Such as, transcription factor binding to an enhancer sequence of DNA regulating the expression of gene X, up-regulates gene expression by enhancing transcription from gene X. The same transcription factor binding to a silencer DNA sequence of the same gene shuts down DNA expression by preventing transcription from taking place.
