Chapter 5. Gene Structure
What are Genes
Genes are basic units of inheritance. Genes hold the information to build and maintain an organism’s cells and pass genetic traits to offspring. All organisms have many genes corresponding to various different biological traits, some of which are immediately visible, such as eye color or number of limbs, and some of which are not, such as blood type or increased risk for specific diseases, or the thousands of basic biochemical processes that comprise life.
The genetic code
The genetic code is the set of rules by which information encoded in genetic material (DNA or mRNA sequences) is translated into proteins (amino acid sequences) by living cells.
The code defines how sequences of three nucleotides, called codons, specify the order in which the 20 naturally occurring amino acids are put together to produce a specific polypeptide during protein synthesis. The existence of a molecular code was predicted by the biochemists even before the DNA was confirmed to be the blueprint of life. The challenge was to understand how the DNA molecule, that consists only of four molecular “letters” (A, T, G, and C) can encode 20 amino acids. The simplest assumption is that one DNA nucleotide specifies one amino acid. This, however, leaves 16 amino acids without a code. If we increase the complexity one step forward, and suppose that two DNA “letters” code for one amino acid. 42=16; we are still four “words” short of 20. Increasing the complexity one step further, we can imagine that a combination of three “letters” specifies one amino acid. 43 = 64; now we have too many “words”, but this this the most parsimonious combination.
The theoretical genetic “vocabulary” was verified experimentally in the early 1960s. It has been determined that of the 64 nucleotide “triplets” (codons), 61 code for amino acids; three out of 64 serve as termination sequences (stop codons) during protein synthesis. Many amino acids are coded by more than one codon (the code is redundant). The ATG codon specifying amino acid methionine also serves as the “start” codon of every eukaryotic gene. ATG is the first codon of a messenger RNA (mRNA) transcript translated by a ribosome during protein synthesis. It does not get incorporated into the polypeptide chain during the synthesis process.
The vast majority of genes are encoded using the same code, but there are also many variant codes. For example, protein synthesis in human mitochondria relies on a genetic code that differs from the standard genetic code.
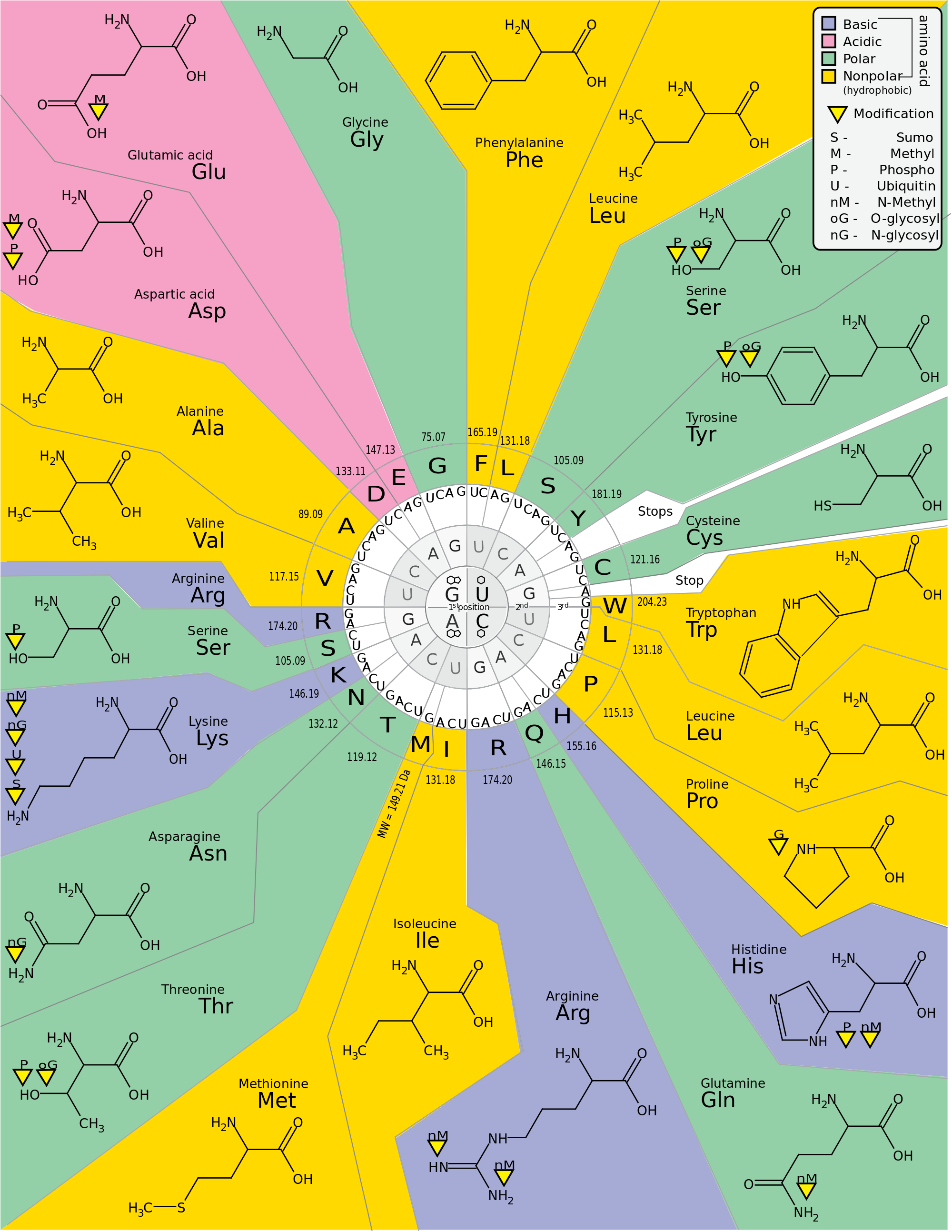
Not every nucleotide in a DNA sequence part of the genetic code. All organisms’ DNA contains regulatory sequences, intergenic segments, chromosomal structural areas, and other non-coding DNA that can contribute greatly to phenotype. Those elements operate under sets of rules that are distinct from the codon-to-amino acid paradigm underlying the genetic code.
Codons appear on the coding (sense) DNA strand as they are read in the 5′ to 3′ direction. Each protein-coding gene is transcribed into a molecule of the related polymer RNA, using the other DNA strand in the double helix (called the template stand).
Therefore, the sequence of nucleotides in the RNA copy of the DNA code appears exactly the same as the code of the DNA, except that the nucleotide thymine (T) of the DNA is replaced by uracil (U) in the RNA. Since the discovery of the genetic code took place through the analysis of RNA copies of the genetic message, the genetic code table is traditionally composed of RNA codons. However, with the rise of computational biology and genomics, proteins have become increasingly studied at a genomic level rather learning about protein composition by isolating mRNA molecules from a cell undergoing gene expression. As a result, the practice of representing the genetic code as a DNA codon table has become more popular.
Structure of a eukaryotic gene
A gene is a sequence of nucleotide triplets of a DNA molecule bound by a start codon (ATG) and a stop codon (TGA, TAA, or TAG) that specifies a cellular product.
Most of the time, the cellular product “coded” in DNA is a protein, in which case the nucleotide triplets in a gene will specify a specific sequence of amino acids on a polypeptide chain. A gene’s final product can, sometimes, be an RNA molecule (rRNA, tRNA).
In humans, like in other eukaryotes, the region of the DNA coding for a protein is usually not continuous. This region is composed of alternating stretches of exons (the actual nucleotide sequences that carry a message delivered to the site of polypeptide assembly) and introns (non-coding “spacer” sequences that take part in regulation of genetic expression at the mRNA level). During transcription, both exons and introns are transcribed onto the messenger RNA (mRNA), in their linear order. Thereafter, a process called splicing takes place, in which, the intron sequences are excised and discarded from the mRNA sequence. The remaining RNA segments, the ones corresponding to the exons are ligated to form the mature RNA strand.
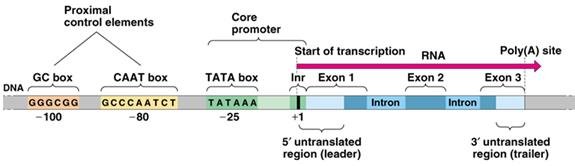
A typical human multi-exon gene starts with the promoter region, which is followed by a transcribed but non-coding region called 5′ untranslated region (5′ UTR), which contains the transcription start site (TSS), followed by the start codon.
The start codon starts the coding sequence of a gene, and it also serves as the translation start site during the translation of mRNA into a chain of polypeptides on the ribosomes. The start codon in eukaryotes is ATG. Following the start codon, there is an alternating series of exons interspersed by internal introns, followed by the terminating exon, which contains the stop codon (either TGA, TAA, or TAG). It is followed by another non-coding region called the 3′ UTR. Ending the gene, there is a stretch of the adenine nucleotide repeating several times (also called the polyadenylation (polyA) tail). The exon-intron boundaries (i.e., the splice sites) are signaled by specific short (2 nucleotide-long) sequences.
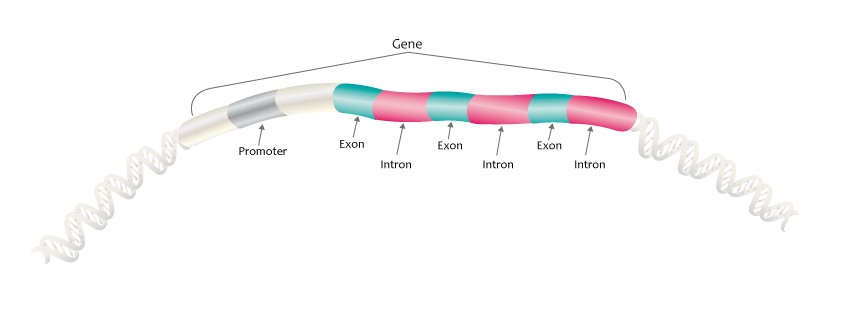
On average, a vertebrate gene is around 30, 000 nucleotides (kilobases, or Kb) long, out of which the coding region is only about 1 Kb long. The average coding region consists of six exons, each about 150 nucleotides (base pairs, since DNA is double stranded, abbreviated as bp) long. Huge deviations from the average are observed. For example, the gene called dystrophin is 2.4 million (Mb) bp long. Blood coagulation-factor VIII has 26 exons whose size varies from 69 bp to 3106 bp, with the total coding region reaching length around 186 Kb and the introns lengths adding up to 32.4 Kb. Intron number 22 produces two transcripts unrelated to this gene, one for each strand. An average 5′ UTR is 750 bp long, but it can be longer and span several exons (for example, in the MAGE family). On average, the 3′ UTR is about 450 bp long, but examples exist where its length 5 Kb (e.g., the gene for Kallman’s syndrome).
Key Takeaways
- The basic unit of genetic inheritance is a gene.
- Genes encode the amino acid structure of proteins using triplets of nucleotides.
- In the genetic code consisting of triplets of nucleotides, some amino acids are encoded redundantly.
A codon is a sequence of three consecutive nucleotides on a polynucleotide chain (DNA or RNA) that corresponds to an amino acid in the polypeptide sequence of a protein.

{kind=link}